자연어 처리를 위한 머신러닝 4기
자연어처리를 위한 머신러닝 CAMP
머신러닝으로 구현하는 자연어 처리의 모든 것. 분석을 위한 이론정리부터 효율적인 텍스트 분석 자동화까지!

- 기간
- 2019. 1. 5 ~ 2019. 3. 16 총 10주
- 일정
- 매주 토요일 14:00 ~ 17:00 주 1회, 총 30시간
- 장소
- 패스트캠퍼스 강남강의장 강남역 4번출구, 미왕빌딩
- 문의
- 02-568-9886help-ds@fastcampus.co.kr
이번 기수는 모집이 마감되었습니다.
출시알림을 신청해주시면,
특별한 혜택과 함께 가장 먼저
다음 기수 모집 소식을 알려드리겠습니다. 감사합니다.
강의목표.
1. 텍스트 분석을 할 때 겪는 가장 현실적인 문제인 ‘노이즈 핸들링’의 해결 방법을 알 수 있습니다.
2. 자연어 처리에 적용하기 위한 머신러닝 알고리즘에 담긴 원리를 이해 할 수 있습니다.
3. 자연어 처리 모델을 스스로 만들어 낼 수 있는 역량을 강화합니다.
자연어 처리를 위한 머신러닝을 배워야 하는 이유.
1. 지저분하고 정제되지 않은 비정형 데이터 처리 해결
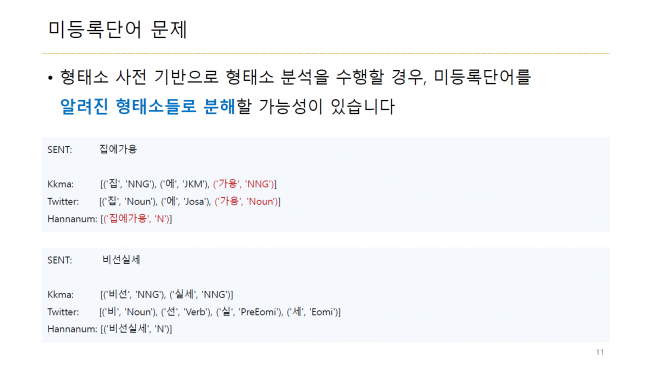
: 한글의 경우, 띄어쓰기가 잘 되어 있으면 문장에서 단어를 구분하는 토크나이징이 쉬워집니다.
예를들어,
– 단어를잘인식할수있다면토크나이징도쉽게할수있습니다. (띄어쓰기 X)
– 단어를 잘 인식할 수 있다면 토크나이징도 쉽게 할 수 있습니다. (띄어쓰기 O)
2. 텍스트 데이터 분석 준비 시간이 짧아집니다.
: 신조어, 전문용어를 사용자 사전에 추가하는 ‘노가다’를 줄이고, 사용자 생성 과정을 데이터 기반으로 추출하여 최대한 자동화 할 수 있습니다.

텍스트 데이터 분석 준비가 아닌,
텍스트 데이터 분석 자체에 더 집중할 수 있습니다.
강의 특징
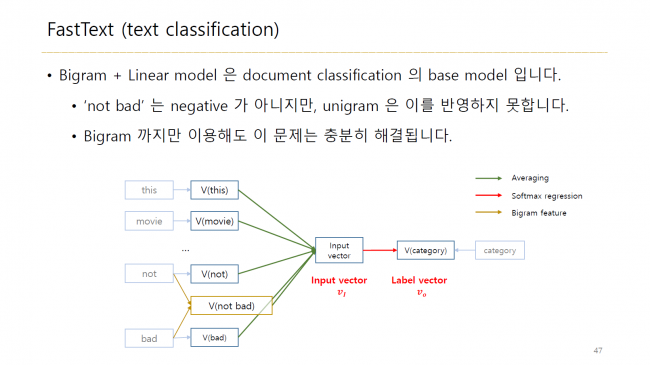
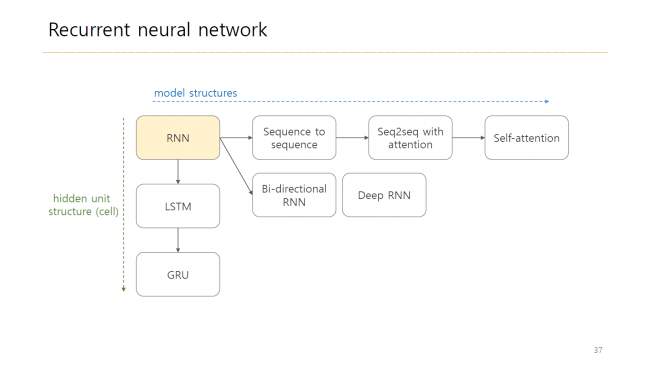
한글 텍스트 분석에 딥러닝을 적용하기 위한 핵심 이론의 정리
실무 분석과 강의 경험이 풍부한 강사님의 데이터 전처리/분석 노하우
머신러닝 알고리즘의 응용을 통해 데이터 특성에 맞는 알고리즘 개발
이미 개발된 라이브러리를 활용한 텍스트 분석 뿐만 아니라,
머신러닝 알고리즘의 응용을 통해
데이터 특성에 맞는 단어 추출, 명사 추출, 띄어쓰기, 키워드 추출 등의
알고리즘을 개발하는 것을 목표로 합니다.

추천 대상

텍스트 데이터를 깨끗하게 정리하기 위한 수작업에 소모되는 시간과 노력을 줄이고 보다 효율적인 한국어 텍스트 분석 기법을 학습하고자 하는 개발자/ 연구원

챗봇 서비스 구현을 위한 데이터 전처리 및 자연어 처리 기법과 데이터에 맞는 알고리즘 개발법을 학습하고 싶은 분.
텍스트 분석을 위한 머신러닝 라이브러리의 작동 원리를 이해하고, 이를 내 업무에 적용해보길 원하시는 분.
비정형 텍스트 데이터, 더이상 막막해 하지마세요.
머신러닝으로 구현하는 자연어 처리의 모든 것!
10주간 이론+실습을 통해
온전히 나의 것으로 만드실 수 있습니다.
커리큘럼
1주차
2-3주차
4주차
5주차
6주차
7주차
8주차
9주차
10주차
-
강의에 대한 전반적인 소개를 한 눈에 보고 싶다면? 교육 과정 소개서를 확인해주세요!
* 본 소개서는 회사 제출용으로도 사용 가능합니다.
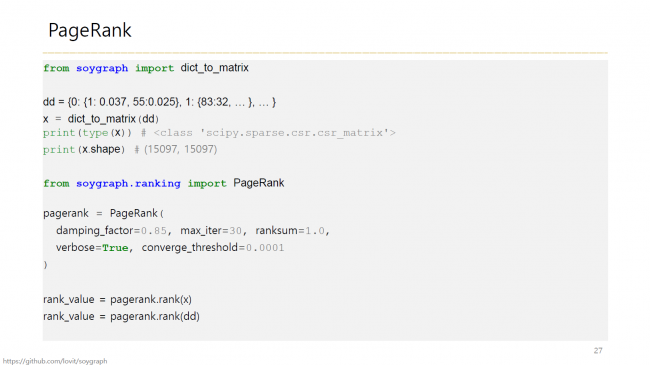
강의 자료 예시

강사 소개

김현중 강사님
머신러닝이 어렵다고 생각하셨던 분들도 머신러닝의 원리를 깨닫고, 그에 따른 ‘로직’이 바로 선다면 그렇게 어렵지 않을 거예요. 본 강의를 통해 ‘문제’라고 생각했던 것을 더 효율적으로 고쳐나갈 자신감을 얻어 가실 수 있도록 최선을 다하겠습니다.
약력
현재 서울대학교 산업공학과 데이터마이닝 연구실에서 박사과정을 밟고 있습니다. 한국어 자연어 처리에 관심이 많으며, 딥러닝 모델들을 어떻게 한국어 자연어 처리 작업에 이용할 수 있을지 고민하고 있습니다. PYCON KOREA 2017에서 ‘노가다 없는 텍스트 분석을 위한 한국어 NLP’라는 주제로 발표하기도 했습니다. 분석가가 가능한 많은 시간을 분석에 이용할 수 있기 위해, 노이즈가 많은 현실 텍스트 데이터로부터 최소한의 노력으로 최대한의 의미를 추출하는 방법들을 고민합니다.
강사님 인터뷰 보기수강 후기
항상 많은 내용을 담아 정성이 느껴지는 강의입니다.
강사님이 많은 경험을 녹이고, 직접 코드를 제공해 주셔서 강의 자료의 질이 높습니다.
자연어 처리에 대한 종합적이고 체계적인 커리큘럼입니다.