자연어처리를 위한 딥러닝 6기
자연어처리를 위한 딥러닝 CAMP
자연어처리에 필요한 딥러닝의 주요 모델, PyTorch 활용법, 자연어처리의 기본개념을 익힐 수 있는 일석삼조의 강의.

- 기간
- 2019. 11. 16 ~ 2020. 1 .11 총 7주
- 일정
- 매주 토요일 14:00 ~ 17:00 주 1회 , 총 21시간
- 장소
- 패스트캠퍼스 강남강의장 강남역 4번출구, 미왕빌딩
- 문의
- 02-568-9886help-ds@fastcampus.co.kr
이번 기수는 모집이 마감되었습니다.
출시알림을 신청해주시면,
특별한 혜택과 함께 가장 먼저
다음 기수 모집 소식을 알려드리겠습니다. 감사합니다.
 ‘자연어처리X딥러닝’ 시작의 첫 걸음!
‘자연어처리X딥러닝’ 시작의 첫 걸음!
강의 듣고! 책도 받아 가자!
강사님 저서 <김기현의 자연어처리 딥러닝 캠프>가 출간되었습니다!
수강을 확정하신 분들께는 개강 첫날, 책 무료 제공이 있을 예정입니다.

강의목표.
PYTORCH를 활용하여, 실제 필드에서 가장 활용도가 높은 기술인
TEXT CLASSIFICATION을 직접 구현할 수 있습니다.
잠깐!
자연어처리와 TEXT CLASSIFICATION의 개념.
정확히 알고 계신가요?
자연어처리
(NATURAL LANGUAGE PROCESSING)
인공지능 분야의 하위 분야로 주로 분류되는 분야로 사람이 사용하는 언어를 기계가 인식할 수 있는 형태로 입력 형식을 바꿔주거나 또는 바뀐 형식을 다시 인간이 이해 할 수 있는 언어로 표현하는 기술을 개발하는 분야입니다.
문서 분류
(TEXT CLASSIFICATION)
Text Classificaion은 실무에서 가장 활용도가 높은 기술입니다. 본 강의에서는 RNN과 CNN을 활용하여 Text Categorization, Sentiment Analysis(감성분석)을 구현할 수 있도록 합니다. 구현 실습은 이어지는 이미지를 참고하세요!
현업에서는 이렇게 쓰입니다

#SENTIMENT ANALYSIS(감성분석)

# LANGUAGE DETECTION(언어탐지)
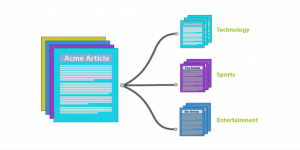
#TOPIC CLASSIFICATION(주제분류)
강의 특징
자연어처리에 필요한 딥러닝의 주요 모델부터
PYTORCH 활용법, 자연어처리의 기본 개념까지
한 번에 세 가지를 모두 익힐 수 있는, 1석 3조의 강의!
NLP
딥핵심개념 완전정복
자연어 처리의 핵심 개념과 최근 연구 동향에 대해 입문자의 눈높이에 맞춰 설명해드립니다. NLP의 초석이라고 할 수 있는 Word Ebbedding과 단어 중의성 해소를 익히고, 다양한 응용을 통해 인사이트를 얻으세요!
PyTorch를 활용한
딥러닝 모델 구현
자연어 처리에 최적화된 PyTorch 환경 설정 방법을 익히고, 활용법을 배워 딥러닝 모델을 만들 수 있습니다. 또한 본 강의를 통해, PyTorch 프레임워크를 활용할 수 있고 선형회귀, 로지스틱 분류 문제를 스스로 풀 수 있게 됩니다.
RNN과 CNN을
활용한 실습
Text Classification은 실제 필드에서 가장 활용도가 높은 기술입니다. RNN과 CNN을 활용하여 감성분석/언어탐지/주제분류 등을 직접 실습해 보세요! 이론으로 이해하고, 실습을 통해 구현해보며 강의 내용을 100% 당신의 것으로 익혀 가세요!
추천 대상

현업에서 감성분석, 문서분류 등을 하고 싶은 분석가 및 개발자

딥러닝을 활용하여 자연어처리를 구현해보고 싶은 분

PyTorch 활용법과 NLP의 기본개념, 두 마리 토끼를 모두 잡고 싶은 분석 초급자
커리큘럼
7주 동안, 자연어처리의 이론과 실습을 동시에 익힐 수 있는 강의.
입문자의 눈높이에 맞춘 커리큘럼으로 시작하세요!
Part 1. 딥러닝 입문
Part 2 자연어 처리 입문
Part 3. 단어 임베딩 백터
Part 4. 텍스트 분류
-
강의에 대한 전반적인 소개를 한 눈에 보고 싶다면? 교육 과정 소개서를 확인해주세요!
* 본 소개서는 회사 제출용으로도 사용 가능합니다.
7주 후, 당신은



수강 후기

수강생 김형규님 후기 인터뷰
수업에서 자연어 처리와 텍스트 분석, 딥러닝에 관한 모든 내용을 새롭게 배워간다는 생각보다는, 기본적인 이론은 미리 공부하고 고민해 본 후에 수업에서는 본인이 학습한 이론에 대해서 강사님께 확인한다는 마음가짐으로 수강하시는게 좋을 것 같습니다. 이렇게 말씀드리는 이유는 수업에서 다루는 내용이 쉽지 않기도 하지만, 수업에서 가져가야 할 내용은 일반적으로 인터넷으로 배울수 있는 내용보다는 강사님의 실전 경험이라고 생각되기 때문입니다. 미리 준비한 만큼 더 많은 것을 얻어 갈 수 있다고 생각됩니다.
후기 인터뷰 자세히 보기
수강생 여민규님 후기 인터뷰
본 코스를 수강한 후 딥러닝과 NLP에 대한 막연함이 해소된 것 같습니다. 스스로 PyTorch 코드를 짤 수 있게 되었고 현업에서 어떻게 활용해야 할지에 대한 가이드라인이 생겼기 때문입니다. 현재는 본 코스에서 학습한 내용을 커뮤니티나 SNS, 상품 후기 등 브랜드와 관련된 소비자의 의견을 취합해 주제와 감성으로 분류하는 일에 활용하고 있습니다. 앞으로는 NLP를 적용하여 소비자의 의견을 파악하는 것에서 더 나아가, 소비자를 세분화하고 각각의 소비자에게 적합한 상품과 광고를 추천해주는 것까지 그 활용 범위를 확대시켜 나가고 싶습니다.
후기 인터뷰 자세히 보기강사 소개

김기현 강사님
현재 MakinaRocks에서 NLP 딥러닝 연구/개발을 맡고 있습니다. 딥러닝 이전 밑바닥부터 다져온 NLP에 대한 핵심 경험들과 필요성에 대해 이야기하고, 자연어처리에 필요한 딥러닝의 주요 모델부터 PYTORCH 활용법, 자연어처리의 기본 개념까지 이해하기 쉽게 가르쳐 드리겠습니다.
약력
– 現 마키나락스 수석연구원 (이상탐지 및 생성 모델 학습 연구/개발)
– 前 SK플래닛 머신인텔리전스랩 (신경망 기계번역 연구/개발 및 상용화 , SK플래닛 SUPEX 수상)
– 前 티켓몬스터 데이터랩 (추천시스템 및 자연어처리 시스템 개발 및 상용화)
– 前 한국전자통신연구원(ETRI) 자동 통역 연구실
(자동 통역(음성인식 및 언어모델) 연구/개발 및 상용화)
(특허기술상(특허청) 충무공상 : 자동통역시스템 발명)
– Qualcomm R&D Korea 인턴 및 표창
– Stony Brook University 컴퓨터공학과 학사/석사
– 한국정보올림피아드(KOI) 19회 동상, 20회 장려상
– 머신러닝 관련 다수 특허 등록
[강의 경험]
– 패스트캠퍼스 PyTorch를 활용한 자연어처리 심화 CAMP 강의
– 패스트캠퍼스 자연어처리를 위한 딥러닝 CAMP
– KT 및 KTDS 자연어처리 강의
– SK그룹 기계번역 강의
– 유튜브 모두의 딥러닝 시즌2 PyTorch 강의 참여

김광우 조교님
약력
– 현 GS SHOP AI센터 빅데이터 플랫폼, 검색 추천 및 분석환경 개발 운영
– SK C&C Data Platform팀 SK Hynix 실시간 분석 환경 구축 프로젝트
– Ticket monster DataLab 빅데이터 및 추천 시스템 운영 및 개발