초격차 : 실무 장애 대응 프로세스로 끝내는 장애율 0% 서비스 운영의 모든 것
Online
실무 장애 대응 프로세스로 끝내는
장애율 0% 서비스 운영의 모든 것

-
01
실습으로 배우는
장애 대응 프로세스의 모든 것직접 경험하지 않고서는 알 수 없는 장애 대응 프로세스의 전반을 100% 실습을 통해서 학습합니다.
-
02
장애 상황 복구부터 회고까지 경험하는
유일무이한 강의
장애 상황을 눈으로 파악하고 복구 후 재발 방지를 위한 회고까지 한번에 하며 진짜 장애 대응 역량을 키워요.
-
03
국내 외 다양한 규모의 기업에서
장애 상황을 경험한 초특급 강사진글로벌 기업부터 스타트업 규모까지, 다양한 규모와 유형의 장애를 대응한 강사진의 노하우를 얻어가세요.
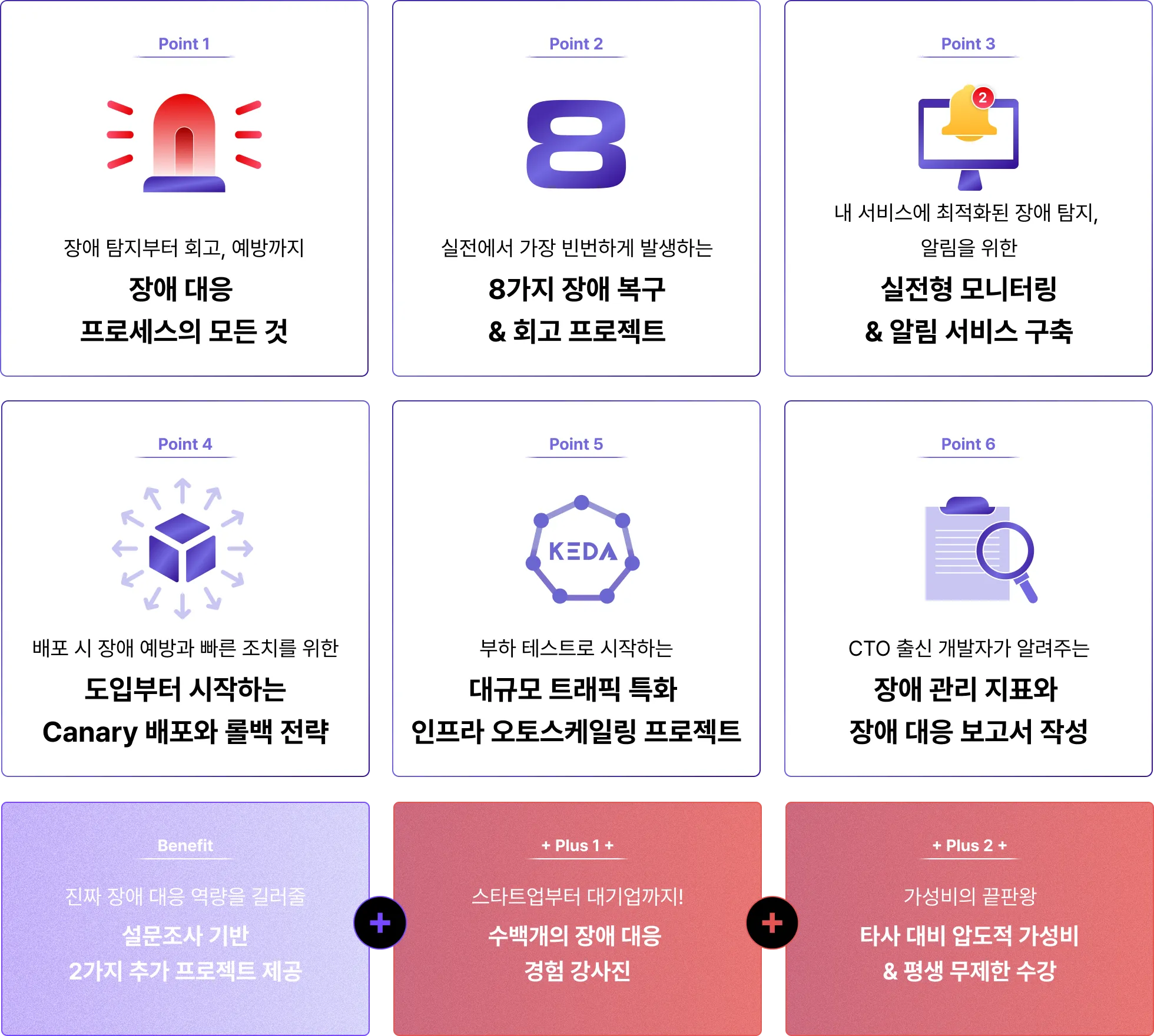
오직 패스트캠퍼스에서만 만날 수 있는
고성능, 고가용성 서비스 운영을 위한 장애 대응의 모든 것!
그 6가지 포인트를 소개합니다.

단 한 번이라도 이러한 고민을 해봤다면
당신에게 이 강의가 더욱 필요합니다.


기술 스택에 대한 이해를 기반으로 실전 장애 상황을 겪어보고 복구하는 모든 프로세스를 담은 단 하나의 강의!
당신에게 실전 장애 대응 역량을 길러줄 수 있는 강의는 오직 패스트캠퍼스에서만 만나볼 수 있습니다.
POINT 1
DevOps, SRE 엔지니어의 필수 역량인
장애 대응 프로세스를 실무 그대로 모두 담았습니다.
더 이상 장애 발생 상황에서 두 손 놓고 죄책감 가지지 않도록 할,
실전 장애 대응 프로세스를 모두 다룬 강의는 패스트캠퍼스가 유일합니다.

POINT 2
100% 실습으로 진행하는 실제 서비스에서 겪는
장애 상황 복구와 회고를 8개의 프로젝트로!
강사님의 스타트업부터 대기업까지 커리어에서 가장 빈번하게 일어났던 장애 케이스만 모았습니다.
실제 서비스에서 발생하는 장애를 눈으로 보고 복구하고 재발 방지를 위해 회고까지 작성하는 방법을 실습해보세요.
이 강의로 실무에서 가장 많이 일어나는 장애 유형 4가지를
8개 케이스로 풀어가며 실전 장애 대응 복구를 완벽하게 정복하세요!

개발서버에서는 단순한 오타부터 서비스 구조의 문제까지, 미처 드러나지 않은 다양한 원인으로 장애가 발생할 수 있습니다.

대규모 트래픽이 발생되면 감지되지 않았던 취약점이 드러나 장애가 발생할 수 있습니다.

스타트업부터 대기업까지! 회사 규모에 관계없이 벌어질 수 있는 데이터베이스 오염은 잘못된 DB조작으로 인하여 장애를 일으킬 수 있습니다.

일정 규모 이상의 시스템은 컴포넌트 간 의존 관계가 점점 복잡해지는데, 이 과정에서 한 컴포넌트에 장애가 발생하면 다른 컴포넌트까지 연쇄작용이 일어나면서, 전면 장애로 번질 수 있습니다.



Q: 이렇게 많은 장애 케이스를 다뤄보는 것이 실제 업무 환경에
어떤 도움을 줄 수 있을까요?
저의 경험상, 회사 규모와 상관 없이 장애는 잊을 만하면 발생했습니다. 잦으면 1주에 1번꼴로 발생하는 것이 장애이기 때문에 회사나 서비스의 규모에 관계 없이 이제는 반드시 갖추어야 하는 역량입니다. 영원히 소규모 서비스만 운영하시고자 한다면 이 강의는 필요하지 않을 수 있습니다. 하지만 더 큰 기업으로 이직하시고자 하는 분들께는 실무 역량 뿐 아니라 이직으로의 발판까지 될 수 있다고 생각합니다.
(전) AWS, (현) 스타트업 Tech Lead | 정윤의 강사님

서비스마다 장애가 다르니깐, 진짜 내가 필요한 장애 케이스만 뽑은
설문조사 기반 추가 프로젝트 [ 2개 혜택 ]을 드립니다!
AWS, 오늘의집, 스타트업 테크리드까지! 국내외 다양한 규모의 기업에서 경험을 쌓은 강사님께 원하는 프로젝트를 배우세요.

* 설문조사는 2024년 7월 15일에 실시합니다.
* 설문조사 결과가 반영된 New 프로젝트는 2024년 8월 중 확정 및 안내됩니다.
* 설문조사는 2024년 4월 15일부터 5월 15일까지 구매하신 수강생분들을 대상으로, 강의 내 질의응답 게시판에서 진행됩니다.
POINT 3
서비스 다운률 0.00009%로 만들어 줄
실전 모니터링 시스템 구축 프로세스
단순한 기술 스택 기반 모니터링 시스템 구축 강의가 아닙니다!
빠른 장애 상황 탐지를 위한 알림 시스템 구축까지, 실전에 200% 활용 가능한 모니터링 시스템 구축 방법을 배워요!
Prometeous & Grafana 단순 사용법만으로는 실전 장애 상황에 대응할 수 없습니다.
운영할 서비스 구축부터 시작하여 서비스 별 모니터링 지표를 제대로 시각화하는
진짜 실전에 필요한 모니터링 서비스 구축을 학습합니다!

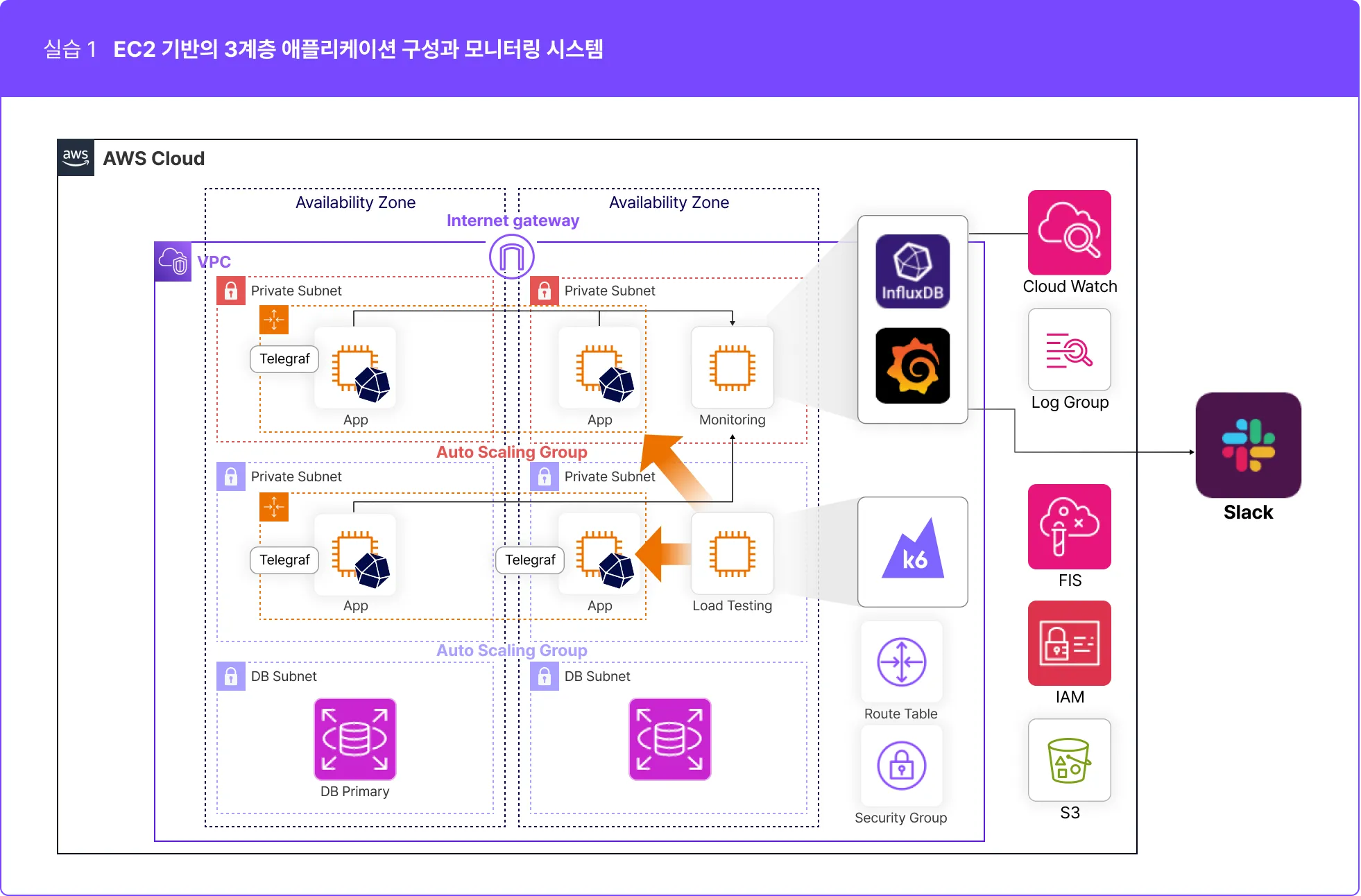


어플리케이션 서버의 로그, 데이터베이스 쿼리 성능, HTTP 요청 및 응답 상태 코드 등과 같은 어플리케이션 레벨의 지표를 모니터링하여 어플리케이션의 성능을 평가하고 사용자 경험을 개선할 수 있습니다.

EC2 기반의 어플리케이션에서는 EC2 인스턴스들과 네트워크 구성을 관리해야 합니다. 이러한 인프라 관리 측면에서 모니터링은 EC2 인스턴스의 CPU, 메모리 사용량, 네트워크 트래픽 등을 모니터링하여 자원 사용량을 최적화하고 장애를 예방할 수 있습니다.

어플리케이션 서버의 로그, 데이터베이스 쿼리 성능, HTTP 요청 및 응답 상태 코드 등과 같은 어플리케이션 레벨의 지표를 모니터링하여 어플리케이션의 성능을 평가하고 사용자 경험을 개선할 수 있습니다.
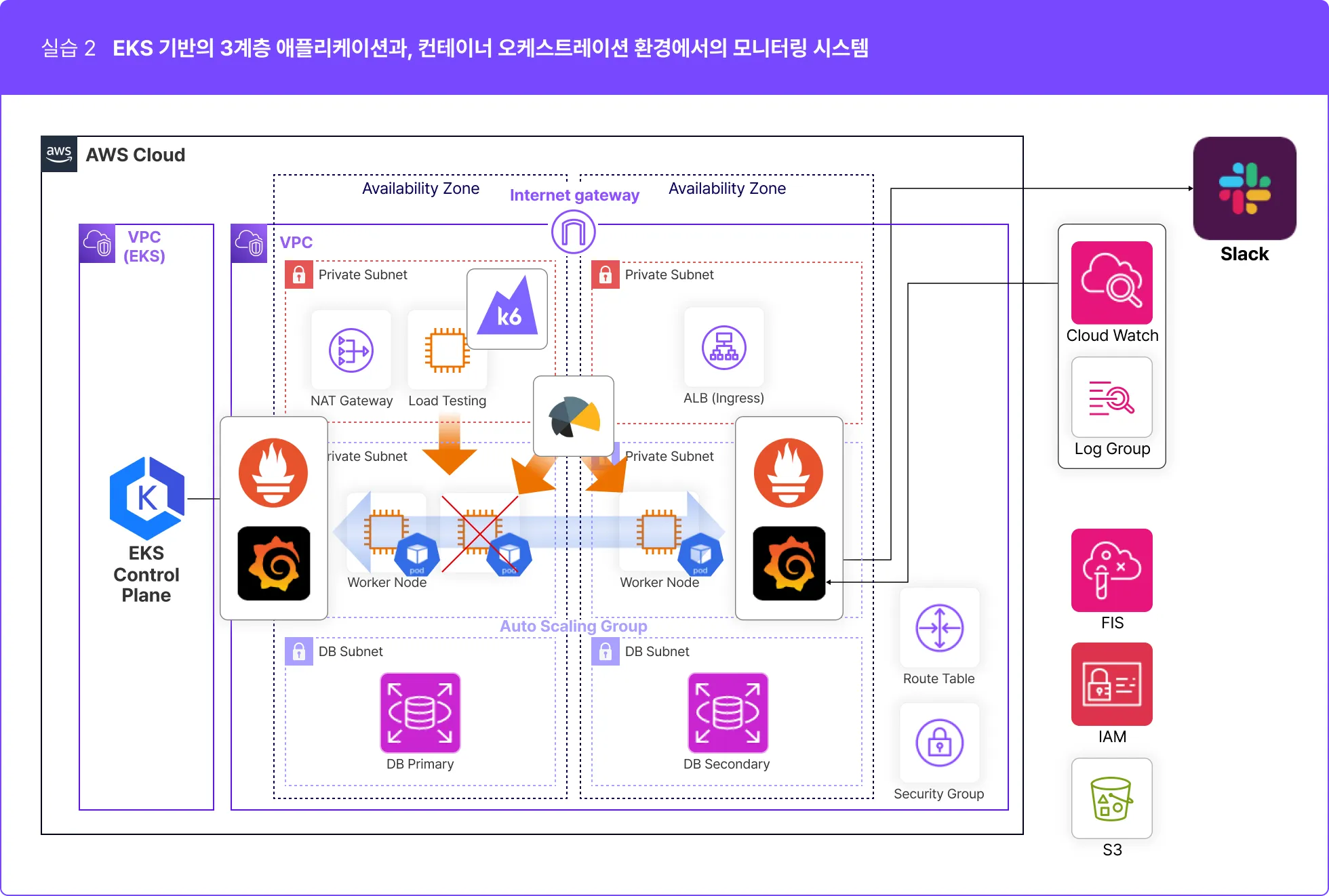


EKS에서는 어플리케이션을 컨테이너로 실행하며, 각 컨테이너는 Pod에 배치됩니다. 따라서 모니터링 시스템은 Pod의 상태, 컨테이너 리소스 사용량(CPU, 메모리), 컨테이너 로그 등을 관리하고 모니터링해야 합니다.

EKS 클러스터는 여러 노드로 구성되며, 각 노드는 여러 Pod를 호스트합니다. 모니터링 시스템은 클러스터 노드의 상태, 노드 간 통신 상태, 클러스터의 확장/축소 이벤트 등을 관리하고 모니터링합니다.

EKS에서는 Kubernetes 서비스를 사용하여 서비스 디스커버리와 로드 밸런싱을 수행합니다. 모니터링 시스템은 서비스의 상태와 로드 밸런서의 트래픽 분산 상태를 관리하고 모니터링합니다.

Q: 이번 프로젝트에서 학습할 수 있는 모니터링 서비스 구축에서의 실무 핵심 포인트는 무엇인가요?
저는 다년간의 실무 경력을 통해 장애율을 현저히 줄일 수 있는 모니터링 전략을 개발하고 실제로 적용한 경험을 가지고 있습니다.
이 과정에서 얻은 실질적인 모니터링 서비스 구축 및 운영에 대한 노하우를 공유할 예정인데요.
이번 강의를 통해 IT 인프라 및 서비스 운영의 안정성 극대화 전략을 학습하실 수 있으며,
이는 IT 대기업 또는 빠른 고객 피드백과 서비스 개발을 요구하는 스타트업에서도
매우 중요한 역량입니다.
(전) 메가존클라우드 (현) 스타트업 개발총괄 | 송지형 강사님
POINT 4
장애가 가장 많이 발생하는 서비스 론칭단을 100% 커버!
Canary 배포 방식으로 알아보는 무중단 배포와 롤백 프로젝트
아무리 개발서버와 실서버의 싱크를 잘 맞추어도 항상 배포에서는 에러가 나기 마련!
장애 예방과 빠른 대응에 최적화된 Canary 배포 방식을 도입부터 제대로 학습하세요!



실무에 한걸음 더 다가서는 Special Point 3가지!

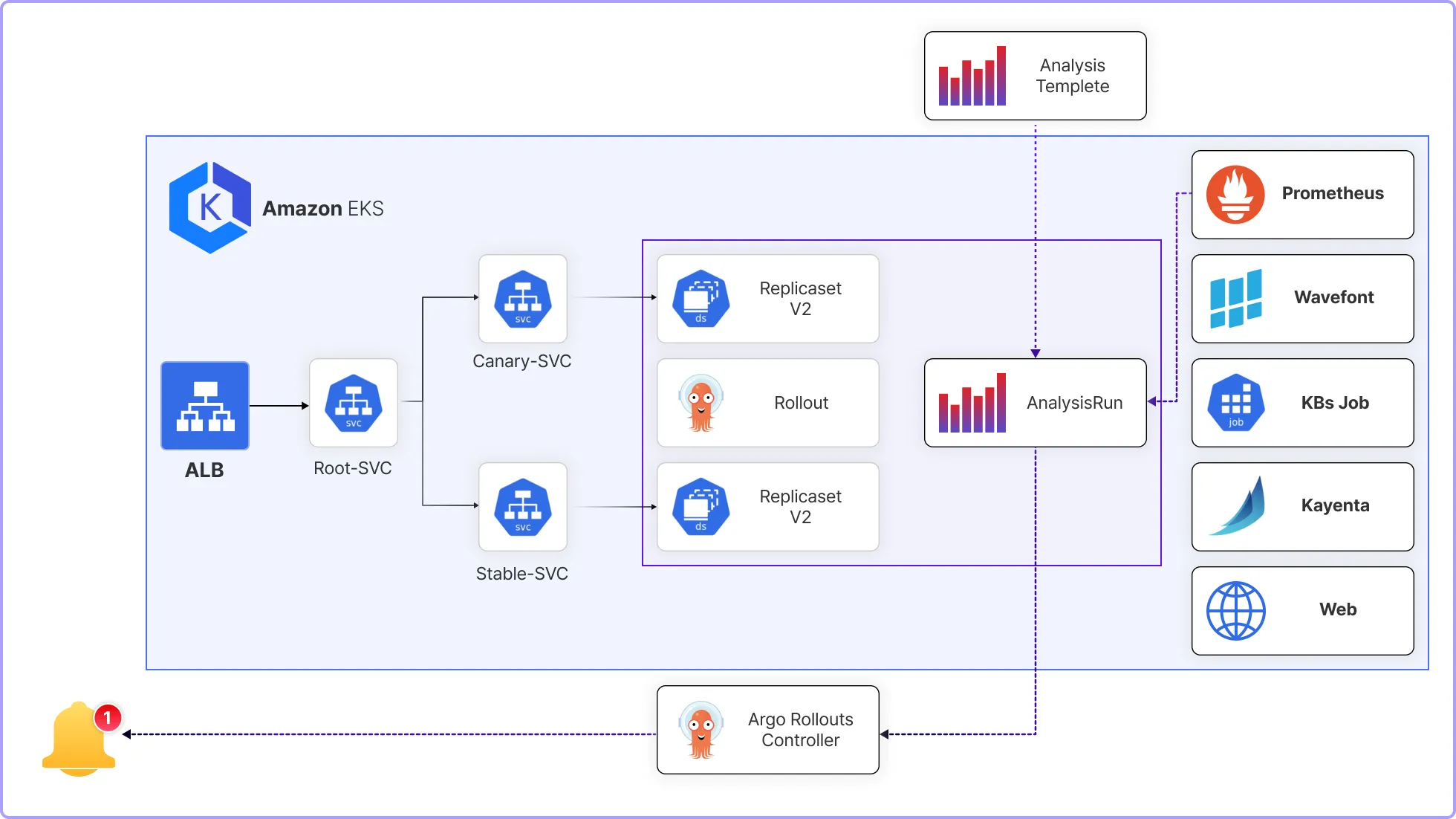
POINT 5
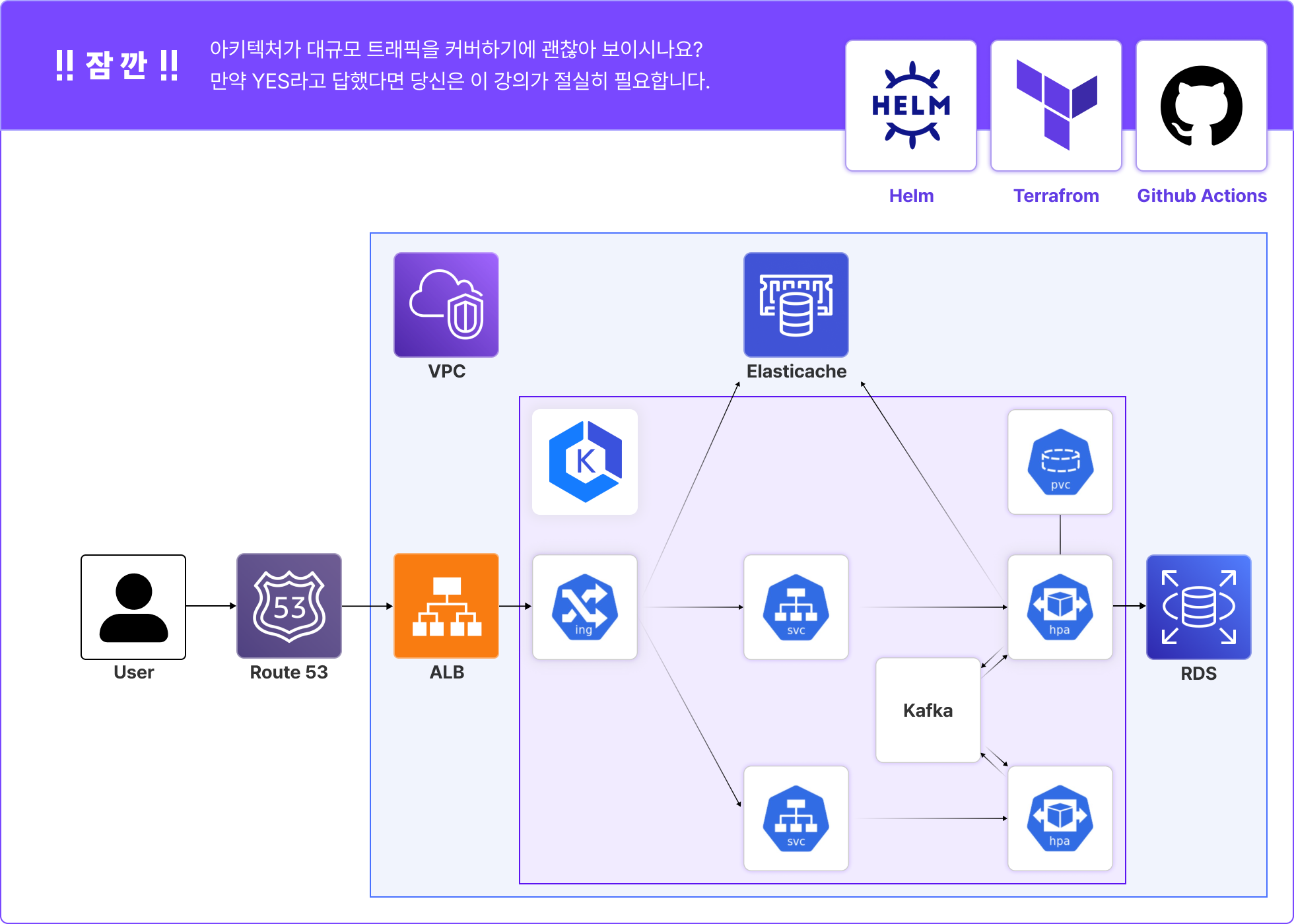
대규모 트래픽에 예상되는 장애를 사전에 차단!
부하 테스트로 시작하는 Kubernetes 오토스케일링
실무 개발자에게는 항상 어려운 오토스케일링!
대규모 트래픽 특화 프로젝트로 장애도 예방하고 적절한 인프라 오토스케일링 방법까지 한 번에 학습하세요!


• 부하테스트 도구 K6 사용 방법
• 부하 테스트 시나리오 설계
• 모니터링 대시보드 구축
• 부하테스트 종류 학습

• 스펙 산정을 위한 부하테스트 실습
• 임계치를 넘어서 발생 하는 장애
• 네트워크 초과
• 커넥션 제한

• keda, 카펜터를 활용한 증설 실습
• 스파이크 트래픽에 대비해 사전 증설 실습
• keda cron 증설 및 스파이크 트래픽 대응 효율성 체크
POINT 6
장애만 해결했다고 끝이 아닙니다. 똑같은 장애가 재발하지 않도록 하는 장애 후속 보고서 작성
10년차 이상의 CTO급 개발자에게 듣는
장애 보고서 작성을 위한 개론과 TIP까지


학습내용
• 장애 심각도
• 장애 발생 시각, 인지 시각, 대응 이력, 해소 시각
• 장애 원인 분석
• 재발 방지 및 장애 후속 조치 방안

학습내용
• 리뷰와 회고의 차이
• 분석 결과 리뷰와 장애 회고 방법

학습내용
• 다양한 장애 지표 소개
- MTBF, MTTD, MTTR, MTTA 및 MTTF
• 실전 장애 관리 및 개선
- 장애 관리 시스템 도입과 활용
- 팀 내 커뮤니케이션과 조율
- 사례 연구 및 시나리오 기반 학습
POINT 7
평균 연차 10년차 이상! 장애를 핸들링 하는 데 이만큼 경험을 가진 강사님은 없습니다.
AWS, KT 등 빅테크 기업 엔지니어들의 진.짜. 실무 꿀팁 대방출

송지형 강사님
• (현) 파트리지시스템즈 개발총괄
• (전) 메가존클라우드 R&D센터 플랫폼개발팀장
• (전) 엔씨소프트 플랫폼 개발 리드
• (전) SK Planet 클라우드엔지니어링
• (전) KT 클라우드엔지니어링
수강생에게 전하는 한마디
본 강의에 등록해 주신 여러분을 진심으로 환영합니다. 여러분은 이미 서비스 운영의 안정성과 장애 대응 능력을 갖추는 데 있어 중요한 첫걸음을 내딛었습니다. 이 강의를 통해 여러분이 실무에서 직면할 수 있는 다양한 도전을 극복하고, 서비스 안정성을 올리는데 큰 도움이 되었으면 합니다. 이 강의를 통해 장애 발생 시 신속하고 효과적으로 대응할 수 있는 능력을 개발할 수 있고, 모니터링 시스템 구축과 운영을 통해 서비스의 안정성을 극대화하는 방법을 배움으로써, 장애율을 현저히 줄이고 IT 서비스 운영에 있어 핵심 인재로 성장할 수 있도록 도와드리겠습니다. 이 강의가 커리어 발전에 있어 중요한 이정표가 되었으면 합니다.

조이정 강사님
• (현) 카카오계열사 SRE
• (전) 클라우드 공급업체 Solutions Architect
• (전) LG 계열사 Cloud Architect
수강생에게 전하는 한마디
안녕하세요, 새로운 패스트캠퍼스 강의에 강사로 참여하게 되어 영광입니다. 주니어 시절 On-premise 시대의 끝자락에서 Cloud 트랜드를 관찰하고 거스를 수 없는 거대한 흐름을 느끼고 쭉 클라우드에 관심을 가지고 커리어를 쌓아왔습니다. 제가 처음 devops를 시작할때 느꼈던 막연한 부담감을 기억합니다. 이제는 '핫'한 기술에서 베이직이 되어가고 있는 kubernetes 기술과, 이를 둘러싼 Microservice / Cloud환경에서 어떻게 장애를 두려워하지 않는 운영자가 될수 있을지에 대한 힌트를 얻게 되시길 기대합니다. 이 강의를 듣는 모든 분들이 실제 현업의 슈퍼맨이 되시길 응원합니다.

정윤의 강사님
• (현) 디비디랩 Tech Lead
• (전) 오늘의집 DevOps Engineer
• (전) AWS Cloud Engineer
수강생에게 전하는 한마디
수 년간 다양한 규모의 회사에서 클라우드 기반의 개발과 시스템 설계를 수행해 온 정윤의라고 합니다. 지금까지 저 역시 정말 많은 장애 상황을 겪어 왔는데, 장애 상황의 그 긴장감과 압박감은 저도 아직 극복이 되지 않습니다. 다만 평소 시스템에 대한 이해와 장애 대응에 대한 준비를 통해 그런 급박한 상황에서도 점점 정확한 판단과 행동을 할 수 있게 되는 것 같습니다. 이번 강의를 수강하시며 다양한 장애 상황의 사례를 검토하여 장애 대응과 시스템에 대한 이해 수준을 높일 수 있다면 좋겠습니다. 여러분도 혹시나 닥칠 수 있는 실제 상황에서 정확한 판단으로 문제를 해결하고, 마음을 진정하고, 제 시간에 퇴근할 수 있기를 바랍니다.

윤진석 강사님
• (현) 위대한상상 Tech Director
• (전) 카카오페이지 Tech Director
• (전) 스푼라디오 Head of R&D
• (전) 여기어때 CTO
수강생에게 전하는 한마디
안녕하세요! 인터넷 서비스 회사에서 무정지 무장애 서비스와 대용량 트래픽 처리를 위한 미들웨어를 개발하는 경험과 오픈소스 커뮤니티에서 데이터베이스와 빅 데이터 플랫폼을 다룬 경험을 가지고 있어요. 시니어로서 프로젝트와 팀을 관리하며 O2O, IoT, 스트리밍 등 다양한 비즈니스 도메인에서 문제 해결과 운영 경험을 쌓았습니다. 이런 경험을 살려 만든 본 강의는 실무에서 필요로 하는 문제 해결 절차와 역량을 향상시켜주며, 서비스 엔지니어링에 대한 자신감을 높일 수 있는 기회입니다. 함께 공부하며 두려움을 이겨내고 자신의 잠재력을 발휘해보세요. 여러분의 성장과 도전을 응원합니다! 🚀✨

수강 중 막히는 부분이 생긴다면?
강사님들이 바로 답변해주시는 질의응답 게시판까지!
✓ A실습 중 에러가 나면? 질의응답 채널을 통해 빠른 해결 !
✓ 강의를 듣는 중 이해가 안가는 부분이 생기면 바로 질문하세요 !
* 본 채널은 2024. 05. 20 ~ 2027. 5. 20 동안 운영 됩니다.
* 강사님이 현업 중 답변하시기에 답변까지 영업일 기준 7일 내외 시간이 소요될 수 있습니다.
POINT 7
타사 어디에서도 찾을 수 없는
압도적인 구성을 가성비 있게
단순 기술 스택 사용 방법을 알려주는 강의가 아닙니다.
진짜 장애 상황을 마주칠 수 있는 국내 유일의 강의를 가성비있게 소장하세요!

강의 수강 후 당신의 서비스에 일어날 변화
 현업에서 실제로 사용하는 모니터링 서비스 구축 방법을 이해하고 사용할 수 있습니다.
현업에서 실제로 사용하는 모니터링 서비스 구축 방법을 이해하고 사용할 수 있습니다.
대규모 트래픽 대응을 위한 알맞은 스펙을 산정하여 안정적인 서비스 운영을 할 수 있습니다.
쿠버네티스 환경을 이해하고 안정적인 서비스 배포를 진행할 수 있습니다.
서비스 배포, 네트워크 문제, 애플리케이션 단의 장애를 빠르게 인지하고 조치할 수 있습니다.
장애 재발 방지를 위한 장애 대응 보고서 작성 방법을 이해하고 사내 문화로 적용할 수 있습니다.
추천 대상

상세 커리큘럼.
아래의 모든 강의를 해당 강의 하나로 모두 들을 수 있습니다.
지금 한 번만 결제하고 모든 강의를 평생 소장하세요!
Part 1. 실전에서의 장애 대응과 문제 해결
Part 2. AWS를 활용한 모니터링 시스템 구축 및 모의 장애 훈련
Part 3. 대규모 트래픽 대응을 위한 사전 증설로 장애 예방하기
Part 4. Canary 적용을 통한 Kubernetes(EKS) 워크로드의 안정적 배포
Part 5. 실전 장애 케이스 8가지 실습과 보고서 작성

해당 강의는 사전 예약 상품입니다.
영상 공개는 다음과 같이 5회에 걸쳐 공개됩니다.
(강의 1회 결제시 모든 영상을 평생 반복 수강 가능합니다.)
-----
1차 공개 24년 05월 20일 (월)
2차 공개 24년 06월 17일 (월)
3차 공개 24년 07월 22일 (월)
4차 공개 24년 08월 19일 (월)
전체 공개 24년 09월 23일 (월)